Xcode5アプリ日本語化初歩の初歩 [Xcode]
Xcodeはもう6のベータ版が出ているので、さして5はもういいと成るかもしれませんが、日本語化のために敢て5で説明すると、画像で見る通りでアプリのひな形を日本語に直せます。
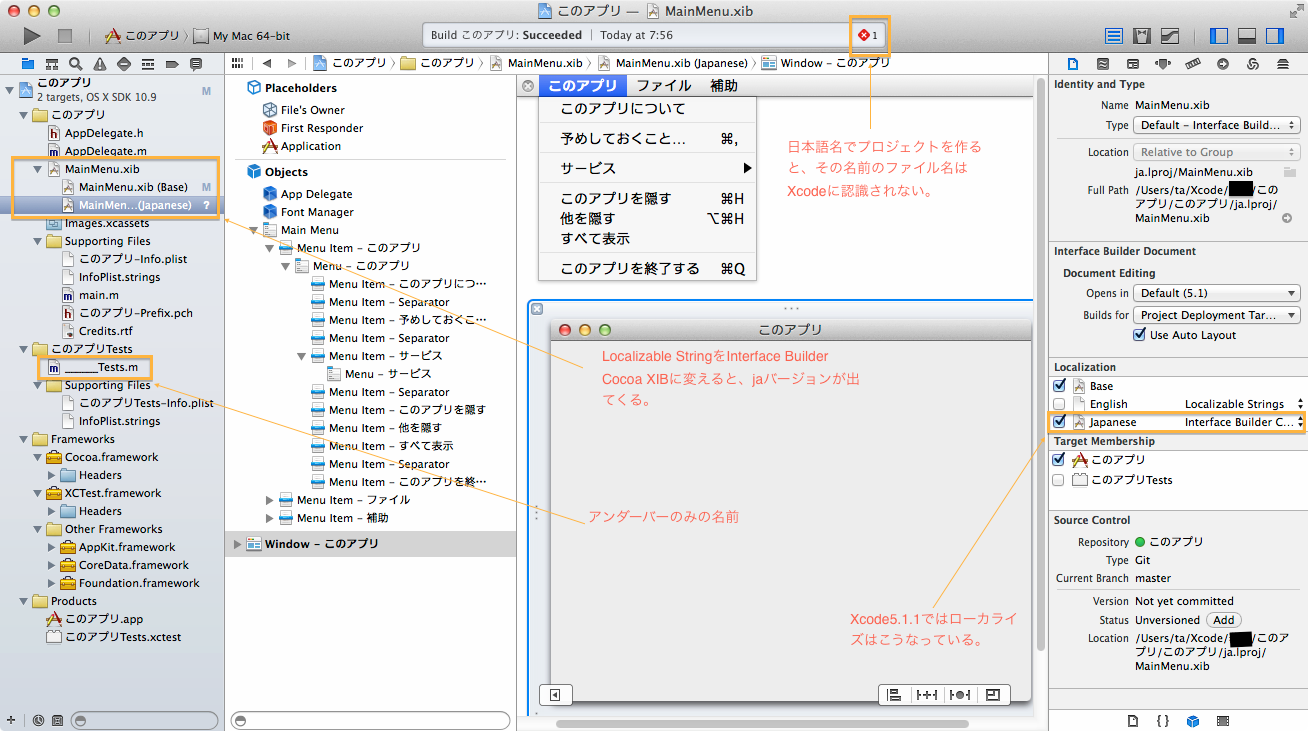
ただ、ネットに今有るような説明の状況ではないようです。これも、ソースコードの日本語化が出来たとしても、アプリ作成でinterface builderを使うと途端にエラーになるので、調べていた時に出て来たのですが、私もXcode5は余使っていなかったので、3.2.6とは大分違っていたのに戸惑いながらやってみました。で思ったのですが日本語に直すのは作りながら最初にやった方が効率が良いんじゃないかと思うのですが、使っている人はどのように使っているのでしょうか。まあこの辺は本や画像でも解りにくいところなので、何度かサンプルで試しながら独歩するしかありません。なのでこれ以降は省略しますが、何度かいじっている間 build ディレクトリとアプリファイルができなくなってしまいました?やり方が悪いのかと何度かやってもダメのようなので、ターミナルからビルドして作ることも出来るようなので、やってみました。$ xcodebuild -target <projectの名前> -configuration Debug (またはRelease)とやるとできるようです。で、これでやると、ビルド中Xcodeが何をやっているか、一目瞭然のようで、かなりなことをしています。これで、ibtoolコマンドを組み合わせるとXcode.appが無くてもビルドできそうですが、参考資料が乏しいので失敗だらけです。また、ローカライズする拡張コマンドには、appleglot があるようで、ダウンロードすれば使えます。なぜコマンドに拘ったかと言うと、Xcodeに内蔵されたInterface Builder からでは、コンパイル済みのライブラリしか受け付けないので、多言語のソースコードのコンパイルのようには行かない事が分かったからです。つまり、リソースもコンパイルしながらアプリをビルドしないと、審問官は許してくれないようです。そこを避けて一部日本語も使えますが、それを探すだけでも今のところ一苦労です。
Xcode6では、Interface Builderが Lang=en だけじゃないものを期待したいところです。
C言語コードを日本語化した時の出来事 [プログラム一般]
次のプログラムコードはC言語で、19の次の素数を求めるプログラムで、例によってサンプルからの抜粋です。これ本当はLinuxで試していたのですが、unary演算子を日本語で置き替えたところで、エラーになってしまいました。コードはこれ二つ:訳語.h
#define 次を用意する int
#define メイン main
//#define 真 true
//#define 偽 false
#define 最初の数 startingPoint
#define 候補 candidate
#define 計算を終えた値 last
#define 整数 i
#define 平方根を取る sqrt
#define 該当するかどうか isPrime
#define プリント printf
#define より等しいか小さい <=
#define かつ &&
#define に次をプラスする +=
#define オブジェクトが等しいとき ==
#define 減算する --
#define 左に右を代入する =
#define 左より右が小さいとき <
#define 右の値を左の値で減じて行った時減じきれない値 %
次の素数.c
#include <stdio.h>
#include <math.h>
#include "訳語.h"
次を用意する メイン( )
{
次を用意する 最初の数, 次の候補, 計算を終えた値, 指定数i;
次を用意する 該当するかどうか;
// 19の次の素数を計算するプログラム
最初の数 左に右を代入する 19;
// ()の条件の時は{ }を行う。該当しない場合は順次先送り
if ( 最初の数 左より右が小さいとき 2 )
{
次の候補 左に右を代入する 2;
}
else if ( 最初の数 オブジェクトが等しいとき 2 )
{
次の候補 左に右を代入する 3;
}
else
{
次の候補 左に右を代入する 最初の数;
if (次の候補 右の値を左の値で減じて行った時減じきれない値 2 オブジェクトが等しいとき 0) /* Test only odd numbers */
次の候補 減算する;
do
{
該当するかどうか 左に右を代入する 1; /* Assume glorious success */
次の候補 に次をプラスする 2; /* Bump to the next number to test */
計算を終えた値 左に右を代入する 平方根を取る( 次の候補 ); /* We'll check to see if 次の候補 */
/* has any factors, from 2 to 計算を終えた値 */
/* Loop through odd numbers only */
for ( 指定数i 左に右を代入する 3; (指定数i より等しいか小さい 計算を終えた値) かつ 該当するかどうか; 指定数i に次をプラスする 2 )
{
if ( (次の候補 右の値を左の値で減じて行った時減じきれない値 指定数i) オブジェクトが等しいとき 0 )
該当するかどうか 左に右を代入する 0;
}
} while ( ! 該当するかどうか );
}
プリント( " %dの次の素数は %d. 満足かい?\n", 最初の数, 次の候補 );
return 0;
}
結果は:
$ cc -o 次の素数 次の素数.c
$ ./次の素
19の次の素数は 23. 満足かい? です。
今回もテストケースとしてやったまでですが、日本文としては、結構読めると思っています。がしかし、これでは丸っきり伝わらないところも出て来て、かえってダメかもの部分も有ります。
それはそれとして、気付かなかったのですが、同じgccだとばっかり思っていたのに、LinixとMacではOS依存のところがあるせいか、若干違って来るんですね。まあ、演算子を日本語にするメリットはまずないでしょうけれど、敢えてやろうとすればMacではできるということで、入門時の説明では使えるかもしれません。ただこれだと演算子の優先順位が全然見えません。表で表せばこの順番通りなはずです。
|
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
02 |
|
! |
“ |
# |
$ |
% |
& |
‘ |
( |
) |
* |
+ |
, |
- |
. |
/ |
|
03 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
: |
; |
< |
= |
> |
? |
|
04 |
@ |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
|
05 |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
[ |
\ |
] |
^ |
_ |
|
06 |
‘ |
a |
b |
c |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
n |
o |
|
07 |
p |
q |
r |
s |
t |
u |
v |
w |
x |
y |
z |
{ |
| |
} |
~ |
|
コンパイラーはこの順位を辿って式を、文を評価していきますから、これが見えなくなると言うことは、この方法は悪い例だと分かります。最もそれを踏まえた上での話なら別ですけど。私自身はこの並びを見るとよく出来てるなあと思うのですが、皆さんはどうでしょうか。で、もう一つ気付くことは、日本語とは不思議なもので、てにをはと言った助詞と言うものが有って、これが結構演算子と似た役割をしているのです。なので、演算子を上のように訳しても不自然さがあまり出ません。英語だと substitutionRightToLeft とかなるんでしょうか。でもこれって文ではないですよね。違いは歴然です。ま、興味が無い人にはどうでもいいんでしょうけれど。
コードに日本語の月名を列挙してみた. [プログラム一般]
前の続きで計算機にscanf()を入れようと思ったのですが、最後までPDFファイルを読むと、これはiPhone用のサンプルに使用する目的で、ありました。そこまで立ち入ると知識が乏しいので、やめて、似たようなものに月名を使ったサンプルがありましたので、こちらを日本語化してみました。コードはいじっているので、その通りではありませんが、scanf の日本語に、「入力を読み込む」を当ててみました。で、何故これを載せたかったかですが、日本語には月名に古来からの個人的には美しい名前があります。これを直接プログラムコードから呼びたかったわけです。コードはこれ:
#import <Foundation/Foundation.h>
#include <訳語.h>
// その月の日本語名と日数を表示する
int main (int argc, char *argv[])
{
自動解放プールを使用
{
列挙 月 { 睦月=1, 如月, 弥生, 卯月, 皐月, 水無月, 文月, 葉月,
長月, 神無月, 霜月, 師走 };
列挙 月 ある月;
int 日数;
ログ (@"月の番号を入力してください: ");
入力を読み込む ("%i", &ある月);
次の時切り替え (ある月)
{
次の時 1:ログ(@"睦月"); 日数=31; 中断;
次の時 3:ログ(@"弥生"); 日数=31; 中断;
次の時 5:ログ(@"皐月"); 日数=31; 中断;
次の時 7:ログ(@"文月"); 日数=31; 中断;
次の時 8:ログ(@"葉月"); 日数=31; 中断;
次の時 10:ログ(@"神無月"); 日数=31; 中断;
次の時 12:ログ(@"師走"); 日数=31; 中断;
次の時 4:ログ(@"卯月"); 日数=30; 中断;
次の時 6:ログ(@"水無月"); 日数=30; 中断;
次の時 9:ログ(@"長月"); 日数=30; 中断;
次の時 11:ログ(@"霜月"); 日数=30; 中断;
次の時 2:ログ(@"如月"); 日数=28; 中断;
default:
ログ (@"月の数字では有りません"); 日数=0; 中断;
}
次の条件の時 ( 日数 !=0 )
ログ (@"その月の日数は %iです。",日数);
次の条件の時 ( ある月==如月 )
ログ (@"...か 29 閏年であれば");
}
return 0;
}
で、このコードでは、さして月名を日本語にする必要が無いように思えますが、応用次第では、使い道はあると思っています。最後の方の、「ある月==如月は」英語では使えないはずです。で、define 定義はどこへ行ったのか、と思われる方もいるかと思いますが、いろいろ試して一々引っ張りだすのも面倒だと思い、訳語.h で/usr/include/ の中にdragdropで、ぶっ込みました。認証でパスワードだけです。再起動もログアウトも必要ありませんが、#ifndef … #endif は付け足しています。こうなれば、ライブラリ、プラグインと自分なりの関数を用意したくなるところですが、大した良いアイディアが浮かんできません。まだそこまでの余裕は生まれないと言うのが実状です。まあ、焦らずぼちぼち行きますか!
Objective-Cでの計算機プログラム日本語化の場合 [プログラム一般]
これは、o’reilyのページからfree Download したObjective-Cのサンプルコードなのですが、計算機のコードで結構スタンダードに知られているコードだと思います。これを、見辛くない程度に日本語化してみました。コードは、$ clang -o 計算機 計算機.m -framework Foundation でコンパイル済みで、結果は、50 とその通りです。
// 計算機クラスの実装
#define 自動解放プールを利用する @autoreleasepool
#define ログ NSLog
#define リリース release
#define クリア clear
#import <Foundation/Foundation.h>
@interface 計算機: NSObject
{
double 累積器;
}
// 累積器 メソッド
-(void) 累積器をセット: (double) 値;
-(void) クリア;
-(double) 累積器;
// 計算 メソッド
-(void) 足し算: (double) 値;
-(void) 引き算: (double) 値;
-(void) かけ算: (double) 値;
-(void) 割り算: (double) 値;
@end
@implementation 計算機
-(void) 累積器をセット: (double) 値
{
累積器 = 値;
}
-(void) クリア
{
累積器 = 0;
}
-(double) 累積器
{
return 累積器;
}
-(void) 足し算: (double) 値
{
累積器 += 値;
}
-(void) 引き算: (double) 値
{
累積器 -= 値;
}
-(void) かけ算: (double) 値
{
累積器 *= 値;
}
-(void) 割り算: (double) 値
{
累積器 /= 値;
}
@end
int main (int argc, char *argv[])
{
自動解放プールを利用する
{
計算機 *卓上計算 = [[計算機 alloc] init];
[卓上計算 累積器をセット: 100.0];
[卓上計算 足し算: 200.];
[卓上計算 割り算: 15.0];
[卓上計算 引き算: 10.0];
[卓上計算 かけ算: 5];
ログ (@"結果は %g", [卓上計算 累積器]);
[卓上計算 リリース];
}
return 0;
}
どうでしょうか、私的には英語で見るよりかなり見やすいのですが、まあ人それぞれなんだと思います。普通であれば入力をして計算をしてもらう使い方ですが、如何せんObjective-C自体に入力関数は有りません。ですから、C の scanf を使うわけですけど、これは後追加で、取り敢えず今回は投稿だけ。
C++サンプルオーバーロードの場合 [プログラム一般]
これは例によってサンプルを自分なりにアレンジしたものなのですが、このサンプルの主題はオーバーロードとなっていて、そのコードの一部です。よりシンプルにしました。
#include <iostream>
using namespace std;
void ディスプレイ( long ロングパラメータ );
void ディスプレイ( char *テキスト);
int main()
{
return 0;
}
void ディスプレイ( long ロングパラメータ )
{
cout << "ロングは: " << ロングパラメータ << "\n";
}
void ディスプレイ( char *テキスト)
{
cout << "テキストは: " << テキスト << "\n";
}
これをターミナルからコンパイルして実行すると、何事も無く一行改行されて、終了します。中身はまだ空っぽです。ディスプレイ関数で表示できるものに、long型とchar型の2種類用意してあります。これで、メインの中にこれら2種類の値を宣言して、ディスプレイ関数で呼び出せばその内容を表示すると言う仕組みで、それをオーバーロードということらしいです。さて何をオーバーロードさせるかと言うと、最初に宣言してあるロングパラメータとテキストです。これは、私が日本語で勝手に付けた名前です。ですので、この名前を使わないで別の名前を使わないとオーバーロードしたことにはなりません。こう追加で宣言しました。
long ロング初期値 = 12345678L;
char *新規テキスト = "エラーになる予定";
ディスプレイ( ロング初期値 );
ディスプレイ( 新規テキスト );
これを、$ clang++ -o テスト1 テスト1.cpp でやると、こんな警告が出ますが、実行ファイルは出来ました。
テスト1.cpp:11:29: warning: conversion from string literal to 'char *' is deprecated
[-Wdeprecated-writable-strings]
char *新規テキスト = "エラーになる予定";
^
1 warning generated.
この警告はあまり気にする必要がないようです。驚いたのはcoutの方で、プロトタイプで指定した値しか受け付けないと思っていたのに、最初はmainの上下の宣言が一致していれば良いようです。つまり、オーバーロード、またはオーバーライト上書きしているようです。では、<< テキスト << 新規テキストに変えるとどうなるでしょうか。やってみました。
テスト1.cpp:24:34: error: use of undeclared identifier '新規テキスト'; did you mean
'テキスト'?
cout << "テキストは: " << 新規テキスト << "\n";
^~~~~~~~~~~~
テキスト
これはさすがに、エラーでした。つまり、外部の関数はもういじれないようです。では、メインの中身はどれくらいいじれるでしょうか、ロングとは整数ですから演算子が使えるかどうか確かめてみます。
long 次のロングの値 = 150L;
long ロング = ロング初期値 + 次のロングの値;
を追加してコンパイルして実行すると、こう結果が返ってきました。
ロングは: 12345678
ロングは: 150
ロングは: 12345828
テキストは: エラーになる予定
期待通りの結果が返ってきましたが、知らない人がこの3行だけ見れば、ロングに三つの値が有るだけで、曖昧です。なので、名前を変えます。と言いたいところですが、外部の関数はもういじれないんだっけ?ここは、思案どころです。表示が順番通りであれば、「ロングは:」の部分は変数にしたいところですが、C C++にそう行った方法があったかどうか思い出せません。なので、外部関数を見直しました。二つを一纏めにして、メイン内で3回呼び出す方法です。コードとしてはこれ:
#include <iostream>
using namespace std;
void ディスプレイ(char *テキスト, long ロングパラメータ );
int main()
{
long ロング初期値 = 12345678L;
long 次のロングの値 = 150L;
long 合計のロング = ロング初期値 + 次のロングの値;
char *新規テキスト1 = "ロング初期値";
char *新規テキスト2 = "次のロングの値";
char *新規テキスト3 = "合計のロング";
ディスプレイ(新規テキスト1, ロング初期値);
ディスプレイ(新規テキスト2, 次のロングの値);
ディスプレイ(新規テキスト3, ロング初期値 + 次のロングの値 + 合計のロング);
// これは二つの値を足した二倍の数値
return 0;
}
void ディスプレイ(char *テキスト, long ロングパラメータ)
{
cout << テキスト << ロングパラメータ << "\n";
}
この結果は期待通り、
ロング初期値12345678
次のロングの値150
合計のロング24691656
と出ました。こんなことでも、結構迷いました。もっと奇麗な方法が有るのか知れませんが、今のは単に数値だから比較的思いついた発想です。では、char同士は同様に足し算できるかどうか、この場合テキスト同士足し算できるかどうか確かめました。
error: invalid operands to binary expression +は使えないようです。もし繋げたいのであれば、第二パラメータをcharに変えてやれば、繋がりました。また、ヘッダーファイルなんかでたびたび使われる「…」もどういう意味なのかこれで使って試してみました。意味としては、この先は何か定義されていても無視して結構です的なことのように思えました。
まあ日本語に変えただけで、今迄やろうとも思わなかったアイデアが生まれることもあるんですねえ!
コードを日本語化すると見えてくるもの [プログラム一般]
今回もデーブさんのサンプルコードでの説明になるのですが、日本語に置き換えると見えてくるものが有るという話です。日本語に置き換えたC++のコードはこれです。
#include <iostream>
//--------------------------------------- このクラスでは
class このクラスでは
{
public:
const short 最大名前の長さ;
short &名目数値;
short 数値;
このクラスでは( short 固定値 );
};
このクラスでは::このクラスでは( short 固定値 )
: 最大名前の長さ( 固定値 ), 名目数値( 数値 )
{
数値 = 最大名前の長さ;
std::cout << "最初の数値 = "
<< 数値 << "\n";
名目数値 += 10;
std::cout << "名目数値に変えた後の数値 = "
<< 数値 << "\n";
}
//--------------------------------------- main()
int main()
{
このクラスでは オブジェクトとして( 10 );
}
これをターミナルから実行するとこう返ってきます。
最初の数値 = 10
名目数値に変えた後の数値 = 20
で、結果だけ求めるのであれば C でも作れるのですが、C++ではクラスでの操作ができますから、これを有効活用するのがC++を使う目的になるわけです。ではやってみましょう。「このクラスでは」ではインスタンスを作れます。では値を20としたインスタンスを追加してみました。「このクラスでは オブジェクトとして( 20 ); 」こうすれば期待通り20と30が表示するかと思いきや、コンパイラーは文句を言ってきました。再定義だと。と言うことは同じ名前だとデプリケートと判断できるのであれば、別名にすれば良いわけですから、次のオブジェクトとして( 30 )を追加しました。期待通り30と40が返ってきました。
これ以上追加しても同じことなので止めるとして、これをもうちょっと機能を追加したいとかいった時、絶えず心の中で英語を繰り返さなければなりません。その手の問題に何の抵抗もない人であれば、それで良いかもしれませんが、普通の人であればもうこのサンプルはいいやって感じになるんじゃないでしょうか。日本に住んで暮らしていれば、聞こえて来る情報、会話は日本語なはずです。プログラム言語に没頭するということは、ややもすると、日本人を忘れることにもなると思います。中にはせっかくプログラミングをするのですから英語で、と言う人もいますが、英語には日本語とは逆順表記の文法も有り、根本的に矛盾するところが有ります。それが疲れるのだと思っています。まして大量のデータを扱うとなれば、尚更です。
まあ、よく周りの名の知れたソフトを見てみれば、大概外国の商品ではないですか、日本は丸っ切り無いとは言いませんが、200MBを超えるソフトとなると、ん~?でどちらかと言うと、それを日本語化するところだけ、やっている感じがするのですが。
話はそれますが、私はMacを使っているのですが、一つ疑問が湧いてくることに、Apple Japanって何をやっているところなのかなあ?と思うことが有ります。ホームページを見れば、本家のホームページをただ日本語化したようなページだし、最近はもし、アメリカのホームページから日本語入力できる機器が注文できるのであれば、キーボードも何もUS製でいいやと思っています。ようは今迄通り使えればどこから買おうが関係無しです。つまり、アップルジャパンとはアップルの日本支店だけの機能しか持っていないんじゃないかと。まあそれほどメジャー扱いでは無いにしてもです。これが、日本人が大いに関わったOSだというなら話は別ですけど、そんな話は聞いたことが有りません。まあ愚痴はこれくらいで、これからのプログラミングは日本人ならそれらしい日本語で!で行きたいかなあ、なんて。
列挙型の日本語化はどうか [プログラム一般]
小出しで申し訳ないのですが、今度はenumを列挙として日本語に変えた場合、どのくらい日本語が使えるかを試してみました。コードは単純なものですが、確かめるには十分です。そのコード:
#include <stdio.h>
#define 列挙 enum
#define プリント printf
列挙 キーテーブル{左, 右, 上, 下};
int main()
{
列挙 キーテーブル キー;
//キー = キーチェック();
キー = 左;
プリント("左 = %d\n", キー);
キー = 右;
プリント("右 = %d\n", キー);
キー = 上;
プリント("上 = %d\n", キー);
キー = 下;
プリント("下 = %d\n", キー);
return 0;
}
これを、Xcodeでビルドしても良いのですが、大げさなのでターミナルからコマンドライン
$ clang 列挙.c -o 列挙
でコンパイルすると警告無しでOKでした。結果は:
左 = 0
右 = 1
上 = 2
下 = 3 でした。ネットにあるサンプルをただ利用させてもらったものです。見ての通り、日本語に置き換えたのは、enum と printf しか有りません。この手の定数はいっぱい有るので、定義し直せば、幾らでも出てきます。直さない方が良い場合も有りますが。また、試していませんがstructも大丈夫そうです。
それで、Xcodeなのですが、この場合何と言ってもアプリケーションを作る時どうなのかです。これ、試しているのですが、コード迄はBuild Succeedと出てくるのですが、何と言ってもインターフェースビルダーのリンクでデバッガーに落ちてしまって、メッセージを確認はするものの、原因は日本語に直した部分ですから、分かりそうなもののどこが悪いのか探せません。まあ言ってしまえば、ものすごく疲れます。頼れるものが何もないのです。まだ、紹介できる段階ではないので出来ませんが、遠回りな方法を辿らなければならなくなったとしても、私の狙いは今のところそれだけですから、挑戦は続きそうです。
コード日本語化している時の出来事 [Xcode]
プログラムで日本語を使うのはいいとしても、如何に理解しやすくして、利用するかによってそんなことをしてまで使う意味があるかどうかと、サンプルを色々試していた時です、信じられないことができているのに気付きました。そんな馬鹿な!と思って何度も確かめましたが、実際可能のようです。今回は全部のコードを載せませんが、画像とそのメイン部分を書いておきます。まあ、C++のコードに慣れている人であれば、自分で簡単なコードを作って確かめられますから、別段意地悪には当たらないと思っています。この画像はMac OSX10.9.3のXcode3.2.6のバージョンで試した時の画像です。またサンプルのコードは例によってデーブマークさんのサンプルです。
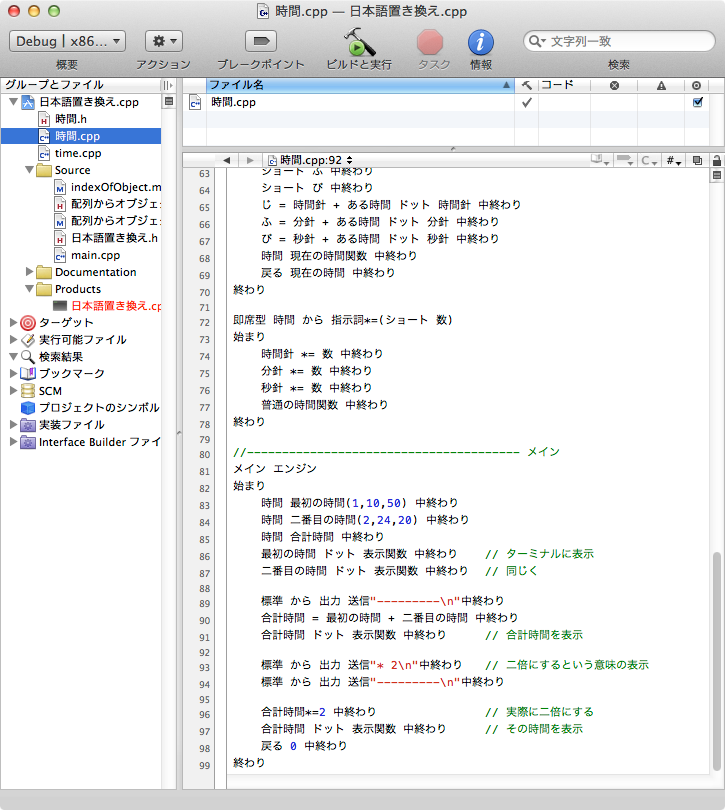
メインの中の関数で外部で日本語化したのは、クラスの時間とその関数群です。このコードの解説はC++の演算子の多重定義の使い方みたいなもので、operatorに言及しているところです。最初日本語部分は、すべて#defineで置き換える程度で考えていたので、そのようにやっていたつもりだったのですが、間違いを直しに直し過ぎて、疲れて来たせいか置き換えていない部分が有るにも関わらず、コンパイルに一応成功したもんだから、気にもしていなかったのですが、ちょっとその部分の表現が可笑しいので直そうと思ったのに、その定義していたつもりの define が有りません。あれれ?状態。これはメインのこの部分です。コード:
//--------------------------------------- メイン
メイン エンジン
始まり
時間 最初の時間(1,10,50) 中終わり
時間 二番目の時間(2,24,20) 中終わり
時間 合計時間 中終わり
最初の時間 ドット 表示関数 中終わり // ターミナルに表示
二番目の時間 ドット 表示関数 中終わり // 同じく
標準 から 出力 送信"---------\n"中終わり
合計時間 = 最初の時間 + 二番目の時間 中終わり
合計時間 ドット 表示関数 中終わり // 合計時間を表示
標準 から 出力 送信"* 2\n"中終わり // 二倍にするという意味の表示
標準 から 出力 送信"---------\n"中終わり
合計時間*=2 中終わり // 実際に二倍にする
合計時間 ドット 表示関数 中終わり // その時間を表示
戻る 0 中終わり
終わり
/***************************************************************************/
の「最初の時間、二番目の時間、合計時間」です。これは英語の部分はどこにもありません。つまり時間クラスがインスタンスとして、日本語のインスタンスを認識したということです。つまり、この方法を使えばわざわざ日本語で定義しなくても、もう日本語が使えるということではないでしょうか。試しているのはこれだけで、ホットニュースとして即上げようと思ったので、もっとテストが必要だとは思いますが、これだけでも私に取っては「たいしたたまげだぁ」です。報告までですけれども、誰かもっと進んだことやってる人いないのかなあ?
Xcode_Objective-C++ [Xcode]
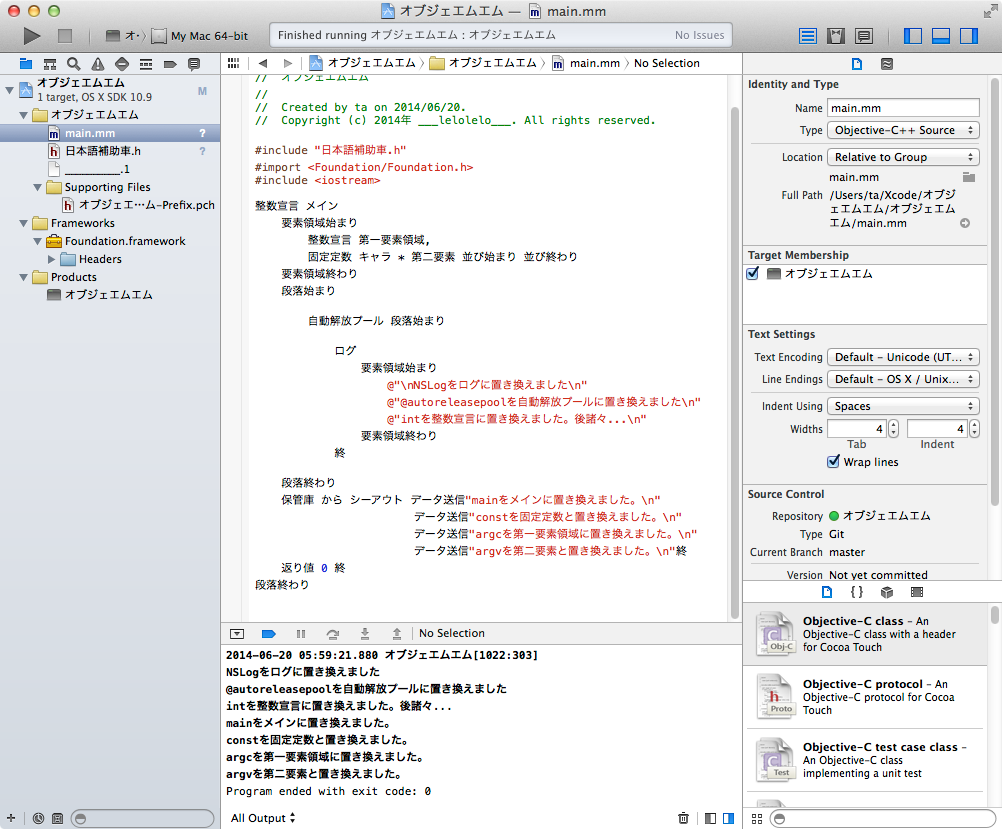
これはXcodeでコードを日本語化した場合、NSLogを使う場合と、C++のcoutを使う場合どちらが見やすく使い勝手が良いかを比較してみた時の、テストです。Objective-C2.0では、自動解放プールから始まり段落終わり迄ですが、iostreamであれば、保管庫から始まり終で終わりで、比較的ストレートで改行してもエラーにならないのですが、@“”の場合は途中で改行するとエラーになってしまうので、@“”を三回使っています。まあ改行しなければ一回で済みますが、コードが見辛くなるのでこうしました。
実際の話、日本語に置き換えると手間が掛かって、かえって煩わしいのですが、あくまでテストであって、ヘッダーファイルの名前を日本語補助車としたのは、理屈がわかった時点、構文の用い方がわかった時点ではずすつもりで、付けています。でも実際やってみないとこれだけの中に知っていないと、エラーになってしまう箇所がいくつか発見できました。それだけでもやってみる価値が私的には有ります。日本語に変えると色(colorSyntax)が無くなってしまうのが残念ですが、それはXcodeが警告やエラーを教えてくれますから、大した気にはならないと思います。
WindowsやLinuxでもできるはずですが、@autoreleasepoolは今現在Macだけなはずですので、前のNSAutoreleasePoolを使うとなると、日本語の部分が更に増えることになります。
このコードをコマンドラインからコンパイルビルドするには、llvm-g++が一番良さそうです。Xcodeはこれを使っているようです。このくらいであれば、g++, c++, clang++でも大した変わらないと思います。このコードはひな形で新規で立ち上げると出てくるコードなので、どこを何に置き換えたは、すぐ分かると思います。
どうでしょう、たまには試してみませんか?
続・C++コードを日本語化する [Xcode]
これ、続きなのですが今度は楽をしてXcode5.1.1でC++ソースコードを日本語化しました。
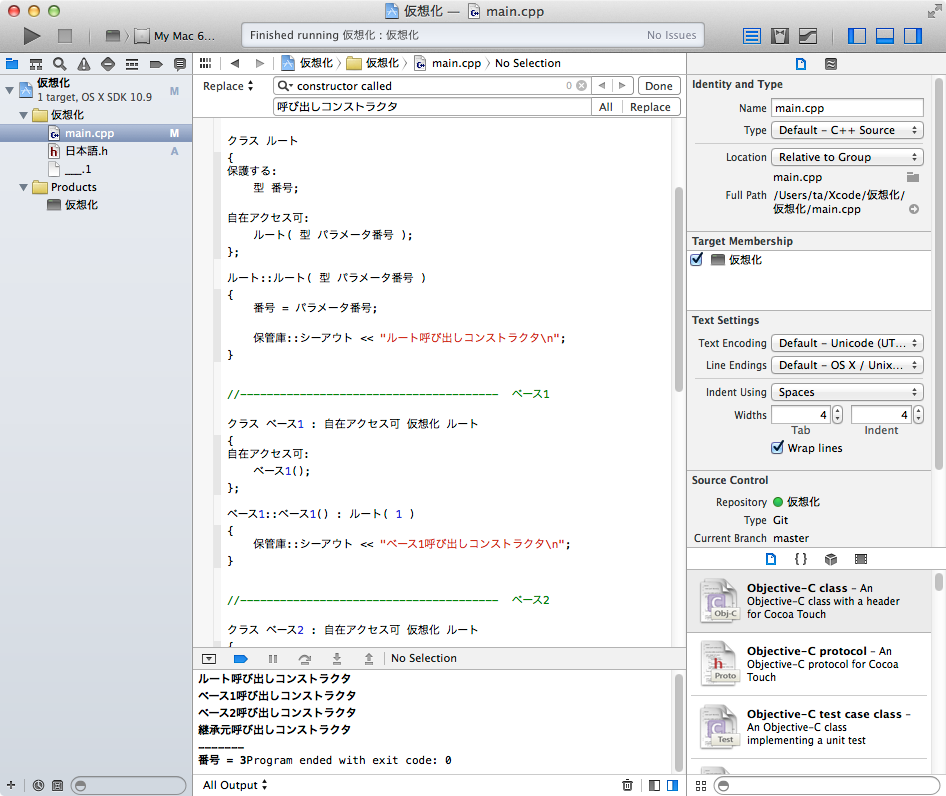
英語の部分は、「” ” : ; , ( ) { } * + - # % & …」「\n」で、つまり演算子の部分だけしませんでした。これは万国共通部分なので、変えてはいけない部分だという認識です。そもそもこれらの演算子は、片言の言葉では表現できない深い働きをするので、それを理解する方が優先です。
この結果は見ての通り、問題なく完了しています。コードの内容はこれ:日本語.h *******
#define 保管庫 std
#define 戻り値 return
#define メイン main
#define 整数宣言 int
#define シーアウト cout
#define 改行 endl
#define 使う using
#define ネーム空間 namespace
#define 汎用型 void
#define 型 short
#define パラメータ param
#define 例題関数 MyFunc
#define クラス class
#define ルート Root
#define パラメータ番号 numParam
#define 番号 num
#define 保護する protected
#define 自在アクセス可 public
#define ベース1 Base1
#define 仮想化 virtual
#define ベース2 Base2
#define 継承する Derived
#define 番号取得 GetNum
#define 新規継承 myDerived
****** main.cpp *******
#include "日本語.h"
#include <iostream>
//--------------------------------------- ルート
クラス ルート
{
保護する:
型 番号;
自在アクセス可:
ルート( 型 パラメータ番号 );
};
ルート::ルート( 型 パラメータ番号 )
{
番号 = パラメータ番号;
保管庫::シーアウト << "ルート呼び出しコンストラクタ\n";
}
//--------------------------------------- ベース1
クラス ベース1 : 自在アクセス可 仮想化 ルート
{
自在アクセス可:
ベース1();
};
ベース1::ベース1() : ルート( 1 )
{
保管庫::シーアウト << "ベース1呼び出しコンストラクタ\n";
}
//--------------------------------------- ベース2
クラス ベース2 : 自在アクセス可 仮想化 ルート
{
自在アクセス可:
ベース2();
};
ベース2::ベース2() : ルート( 2 )
{
保管庫::シーアウト << "ベース2呼び出しコンストラクタ\n";
}
//--------------------------------------- 継承する
クラス 継承する : 自在アクセス可 ベース1, 自在アクセス可 ベース2
{
自在アクセス可:
継承する();
型 番号取得();
};
継承する::継承する() : ルート( 3 )
{
保管庫::シーアウト << "継承元呼び出しコンストラクタ\n";
}
型 継承する::番号取得()
{
戻り値( 番号 );
}
//--------------------------------------- メイン()
整数宣言 メイン(整数宣言 argc, const char * argv[])
{
継承する 新規継承;
保管庫::シーアウト << "-------\n"
<< "番号 = " << 新規継承.番号取得();
戻り値 0;
}
このコードはCodeWarriorのwin95からまた持ち出したものですが、wineで問題なく動く古いコードですけど今でも変わらずコンパイルできます。元々Mac用にも動くコードですから何々に特化した使用にはなっていません。そのようなものは月日が経つと自然に消滅していくものだと思います。
このXcodeを使った時のメリットは、先にヘッダーファイルに置き換えたい英語を定義しておけば、コンパイラーはそれを認識して、間違った語句、ないものを入力した時入力した時点で、赤丸マークで教えてくれます。また見えない日本語の空白などを間違って入力すると、三角黄色印でこれも教えてくれます。今時のIDEは大概この機能はありますけど。
で、いろいろ試して行くとこのやり方では、g++ でもコンパイルできるようでした。これはMacのX11からgeanyで試した時に気付きました。その時の画像:
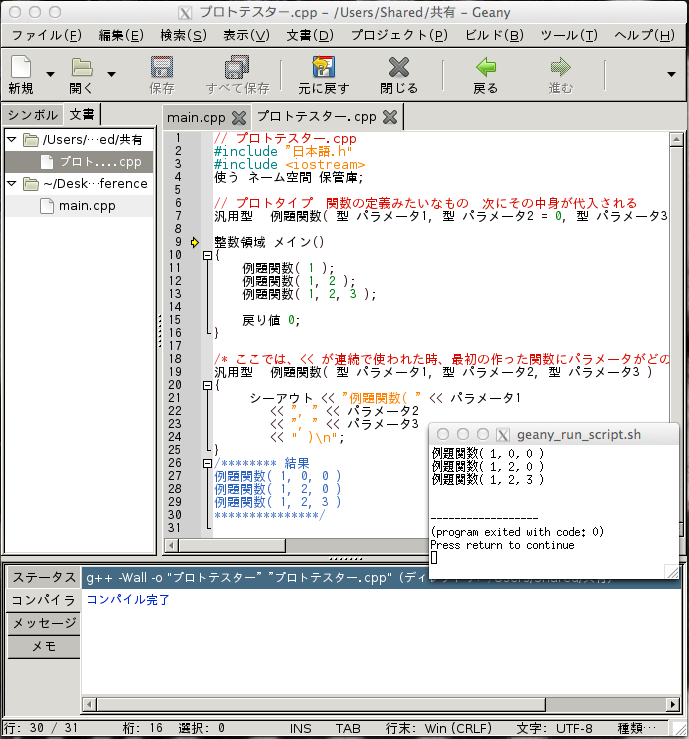
つまり、Linuxでも当たり前にコンパイルできるようです。まあこうなればファイルはUSBメモリなんかに保存しなくてもMac側から共有ディレクトリを作っておけばすべてのOSからアクセスできます。今このディスクには6種類のLinuxが入っているので、同じファイルを使えます。ただし、Mac使用時にはLinuxは見ることができないので、あくまでMac側に作っています。
で、実際日本語化してコードが読みやすく理解し易いのかというと、ん~どうでしょうか。私自身はこのコードが何を目的で作られているのか既に知っていいるので、何とも言い難いところではありますが、役立つかどうかは、訳し方の持って行き処なのだと思います。つまり、なるだけ文章として繋がるようになっていれば、そこそこためになるのではないでしょうか。まあ私自身はその醍醐味を探し出した時の感激を味わうしかないのですが、それを依頼形式にしたとすると、また立場は違ってくるのでしょうか。私自身はこれらの挑戦はコードがなくならない限り続くもんだと思っています。



